For my dissertation I performed an investigation into the different algorithms used by source code plagiarism detectors. This involved extending an existing plagiarism detector called Sherlock with three additional algorithms. These were: an attribute counting algorithm, the Greedy-String-Tiling algorithm used by JPlag, and the Winnowing algorithm used by MOSS. In this post I'll briefly go over each of the algorithms and how they where implemented.
Attribute Counting
Attribute counting methods work by comparing the counts of certain attributes between submissions, such as the number of operators or statements. These methods were used by some of the earliest plagiarism detectors. I implemented an attribute counting algorithm based on Grier's Accuse system [1], which compares submissions based on the following seven attributes:
- Unique operators
- Unique operands
- Total operators
- Total operands
- Code lines (ignoring blank and comment lines)
- Variables declared (and used)
- Total control statements
Greedy-String-Tiling
JPlag (https://github.com/jplag/JPlag) is a popular open-source plagiarism detection tool which uses an algorithm called Greedy-String-Tiling.
The JPlag algorithm works in two stages. First, the input submissions are converted into a stream of tokens, then the token streams are compared using Greedy-String-Tiling [2]. The tokenization is the only language-dependent part of the algorithm, and the tokens are chosen such that they contain semantic information about the program. For example, it uses a BEGINMETHOD token instead of just an OPEN_BRACE.
Two tokenized programs are then compared to find matching sections.
The Greedy-String-Tiling algorithm used has the following three desirable properties:
- A token from one program can only be matched with exactly one token from the other program
- Matches are found independent of position in the program
- Longer matches are preferred over short ones
The similarity between the two programs is the percentage of the token stream that has been matched.
High-level psuedocode of the main algorithm:
output = empty array
do {
matches = empty array
for each unmarked k-gram in the smaller file {
for each unmarked matching k-gram in the larger file {
extend the match as far as possible
if this match is the new largest found {
matches = only this match
} else if this match is as large as the largest {
add the match to matches
}
}
}
for each match in matches {
mark all the tokens in the match
add the match to output
}
} while (largest match found > minimum match length)
The worst case run time complexity is $\mathcal{O}(n^3)$, but JPlag adds optimisations that bring the average complexity for practical cases down to about $\mathcal{O}(n)$
Winnowing
MOSS (Measure Of Software Similarity) is another popular plagiarism detector that is provided as an internet service. MOSS uses a document fingerprinting algorithm called 'Winnowing'[3]. This algorithm works by converting the input into a series of k-grams, hashing each one, and then selecting a subset of these hashes to act as the 'fingerprint' of the submission by moving a window through the hashes and, within each window, choosing one of the hashes. The fingerprints of two submissions are then compared, rather than the submissions themselves, reducing the overall number of comparisons required.
The Winnowing algorithm has some desirable properties. One is that no matches shorter than $k$ are detected, preventing spurious matches. For this reason, $k$ is also referred to as the noise threshold. The algorithm is also guaranteed to detect matches of at least size $t = w + k - 1$, where $w$ is the window length, which is why $t$ is called the guarantee threshold. The noise and guarantee thresholds are parameters that are configurable by the user.
Here is the main loop of the fingerprint generation:
for (int i = 0; i < kgrams.length; i++) {
// move the window to the right
r = Math.floorMod(r+1, w);
window[r] = kgrams[i];
if (min == r) {
// The previous minimum is no longer in the window.
// Scan the window to find the rightmost minimal hash
for (int j = Math.floorMod(r-1, w); j != r; j=Math.floorMod(j-1+w, w)) {
if (window[j].getHash() < window[min].getHash())
min = j;
}
fingerprint.add(window[min]);
} else {
// The previous minimum is still in the window.
// Compare against the new value and update min if necessary
if (window[r].getHash() <= window[min].getHash()) {
min = r;
fingerprint.add(window[min]);
}
}
}
return fingerprint.toArray(new KGram[fingerprint.size()]);
This algorithm moves a window (window size = $t-k+1$) through the $k$-grams to the right, each time selecting the one with the rightmost minimal hash. The array window acts as a circular queue, keeping track of the k-grams in the window. The variable r keeps track of the rightmost index in the circular queue.
When a new hash enters the window we check to see if it's the new minimum and if it is, we add it to the fingerprint. Similarly, if the old minimum hash has left the window, the new minimum is found and added to the fingerprint.
Sherlock
As previously mentioned, these algorithms were implemented on top of the existing Sherlock plagiarism detector. This was because Sherlock provides a convenient platform for uploading submissions and displaying results, which meant that new software would not have to be created from scratch, saving time. Sherlock was also chosen because of its modular nature, making it easy to extend its functionality with new algorithms. The module was written in Java, and Gradle was used for automating the build process.
There are five main components to a Sherlock module:
- Pre-processors: These take in the raw submission and process it to remove unnecessary features such as comments or whitespace.
- Detector worker: This class receives the pre-processed lines for two submissions and performs the comparison algorithm.
- Detector: Configures the detector worker, allocating pre-processors and adding metadata such as the name and description to show in the Sherlock UI.
- Post-processor: Transforms the output result from the detector into a format Sherlock can understand.
- Main class: This class registers the pre-processors, detector, and post-processor with the Sherlock registry so that they can be loaded by Sherlock.
Each of the implemented detectors have a similar class structure. Here is the class diagram for the attribute counting detector:
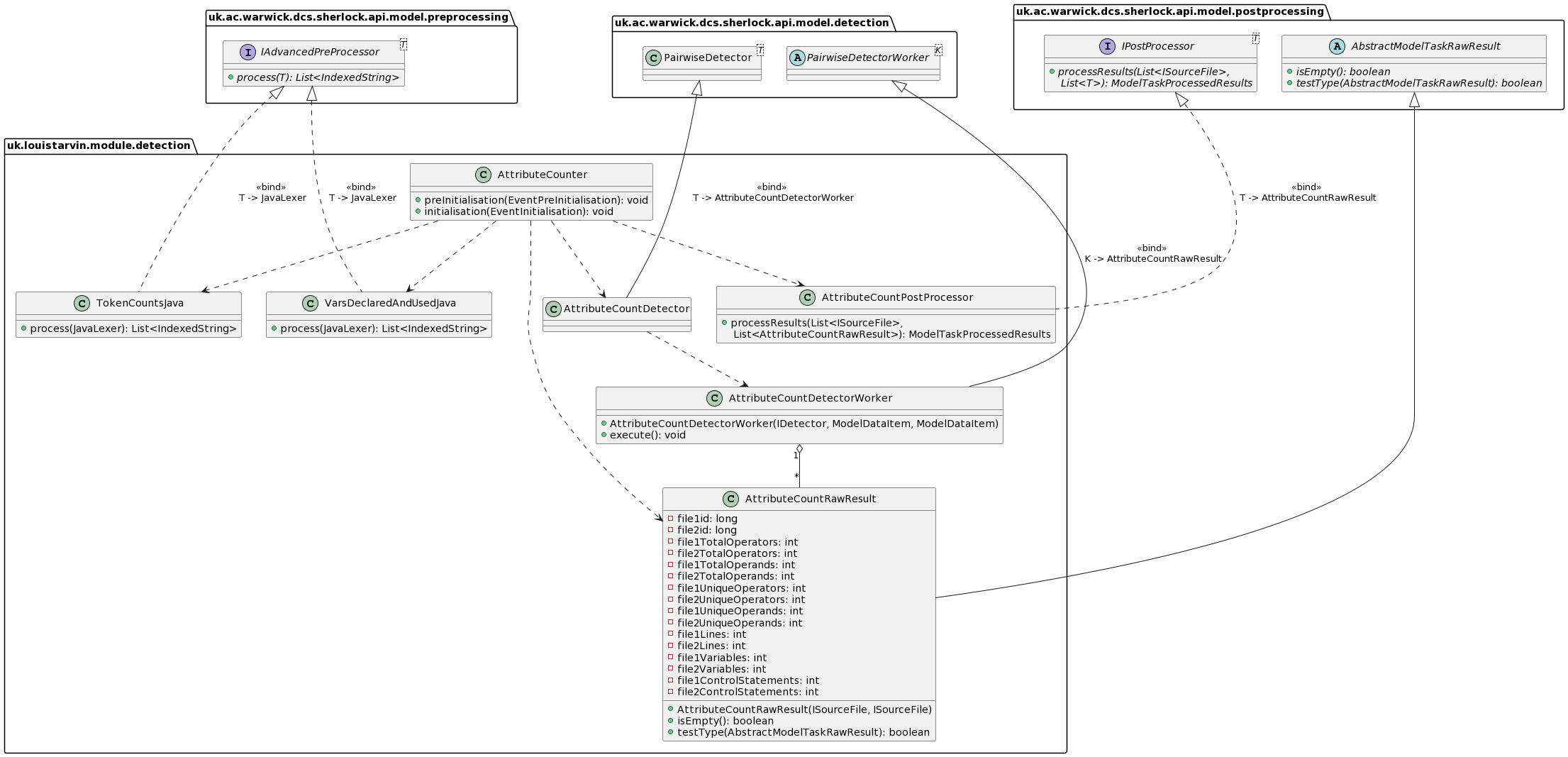
The source code is available here
References:
[1] Grier, Sam. ‘A Tool That Detects Plagiarism in Pascal Programs’. In Proceedings of the Twelfth SIGCSE Technical Symposium on Computer Science Education, 15–20. SIGCSE ’81. New York, NY, USA: Association for Computing Machinery, 1981. https://doi.org/10.1145/800037.800954.
[2] ‘JPlag: finding plagiarisms among a set of programs’, 2000. https://doi.org/10.5445/IR/542000.
[3] Schleimer, Saul, Daniel S. Wilkerson, and Alex Aiken. ‘Winnowing: Local Algorithms for Document Fingerprinting’. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, 76–85. SIGMOD ’03. New York, NY, USA: Association for Computing Machinery, 2003. https://doi.org/10.1145/872757.872770.